AI Existential Risk: My Understanding of the Arguments
Note: substantially updated on 2023-06-19.
This post lays out the case for taking existential risk from AI seriously.
I'm claiming the following 3 things:
- It's likely that we will create AI systems which are much more capable than humans at most tasks (so-called "Artificial General Intelligence")
- Without significant effort, it's likely that these AGI systems will have goals and motivations that are meaningfully different to human goals & motivations
- In this case, the outcomes could be very bad for humans
These are really big claims, and I understand that they sound pretty sci-fi and implausible to begin with. I'm going to try to convince without using any fancy argumentation or sophistry, and instead focus on presenting evidence and conveying intuition. The target audience for this blog post isn't philosophers or researchers, but tech workers, especially those that I work with at SumUp.
The case for Artificial General Intelligence
There are 2 main reasons to believe AGI is coming. Firstly, look at what experts say. Secondly, look at the trajectory of progress and ask when we think that will stop.
Here are a few expert opinions:
- In 2022, a survey of AI researchers (who have published at ICML or NeurIPS, the most prestigious ML conferences in the world) found that, on average, the researchers assigned 50% probability to human-level AI arriving by 2060 [^1]
- Metaculus, a community of expert forecasters with an excellent track record [^2], predicts with 90% confidence that human-level AI will arrive by 2040 [^3]
- There are a handful of elite academics whose entire job is forecasting AI timelines. One extremely thorough report forecasting AI progress using evidence from biology [^4], and another (also exhaustive) report forecasts using estimates of computing power [^5]. Both reports are broadly in line with the predictions above.
Now, you might not trust experts, or you might want to understand why they believe this thing (which is pretty out there). For rigorous arguments, I'd recommend reading one of the reports I linked above, but to get some sense of why this is plausible, it's pretty simple. Consider any of the following graphs:
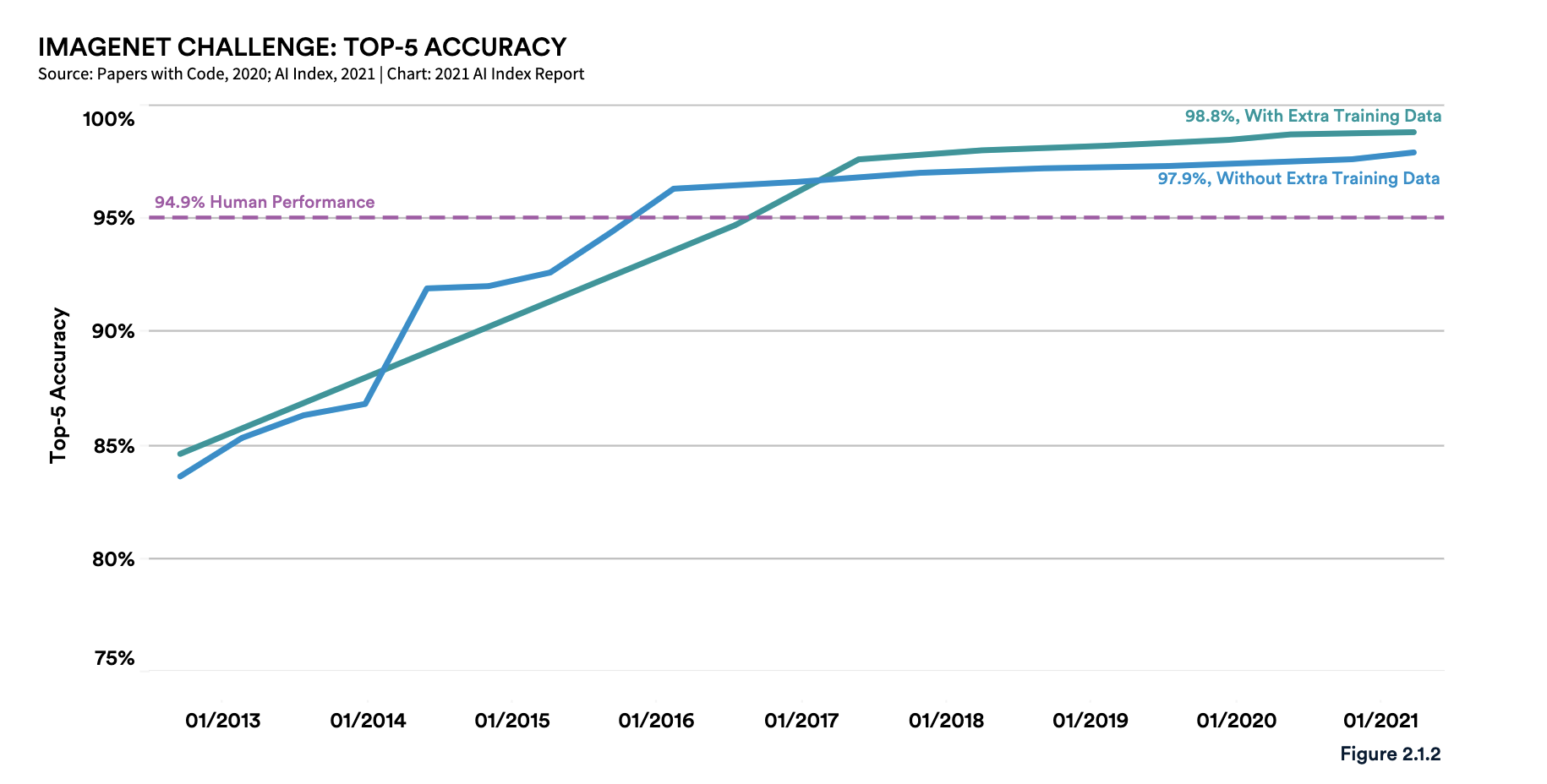 ImageNet Top-5 Accuracy. Image credit: Stanford University [^6]
ImageNet Top-5 Accuracy. Image credit: Stanford University [^6]
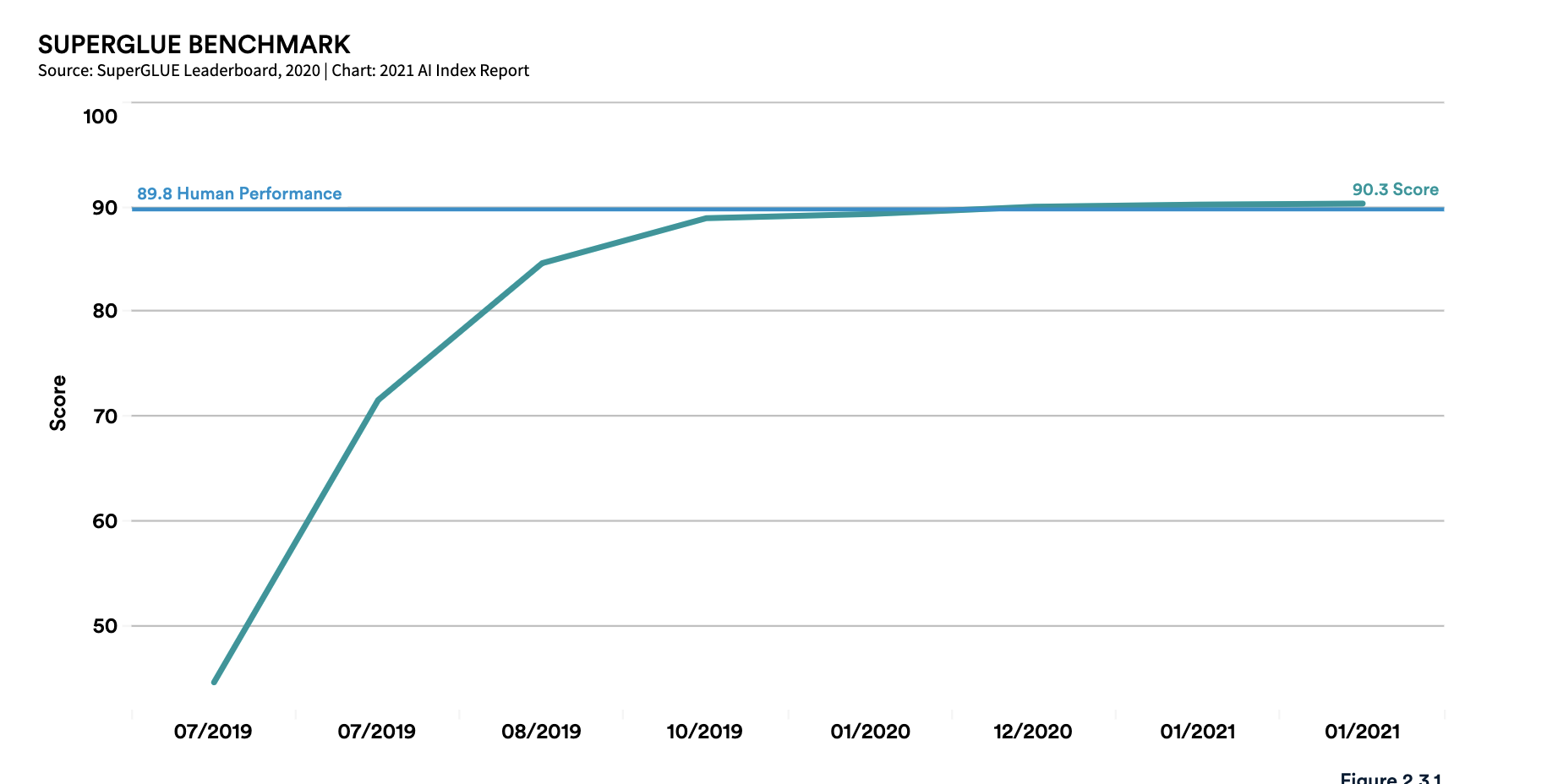 SuperGlue Benchmark performance. Image credit: Stanford University [^6]
SuperGlue Benchmark performance. Image credit: Stanford University [^6]
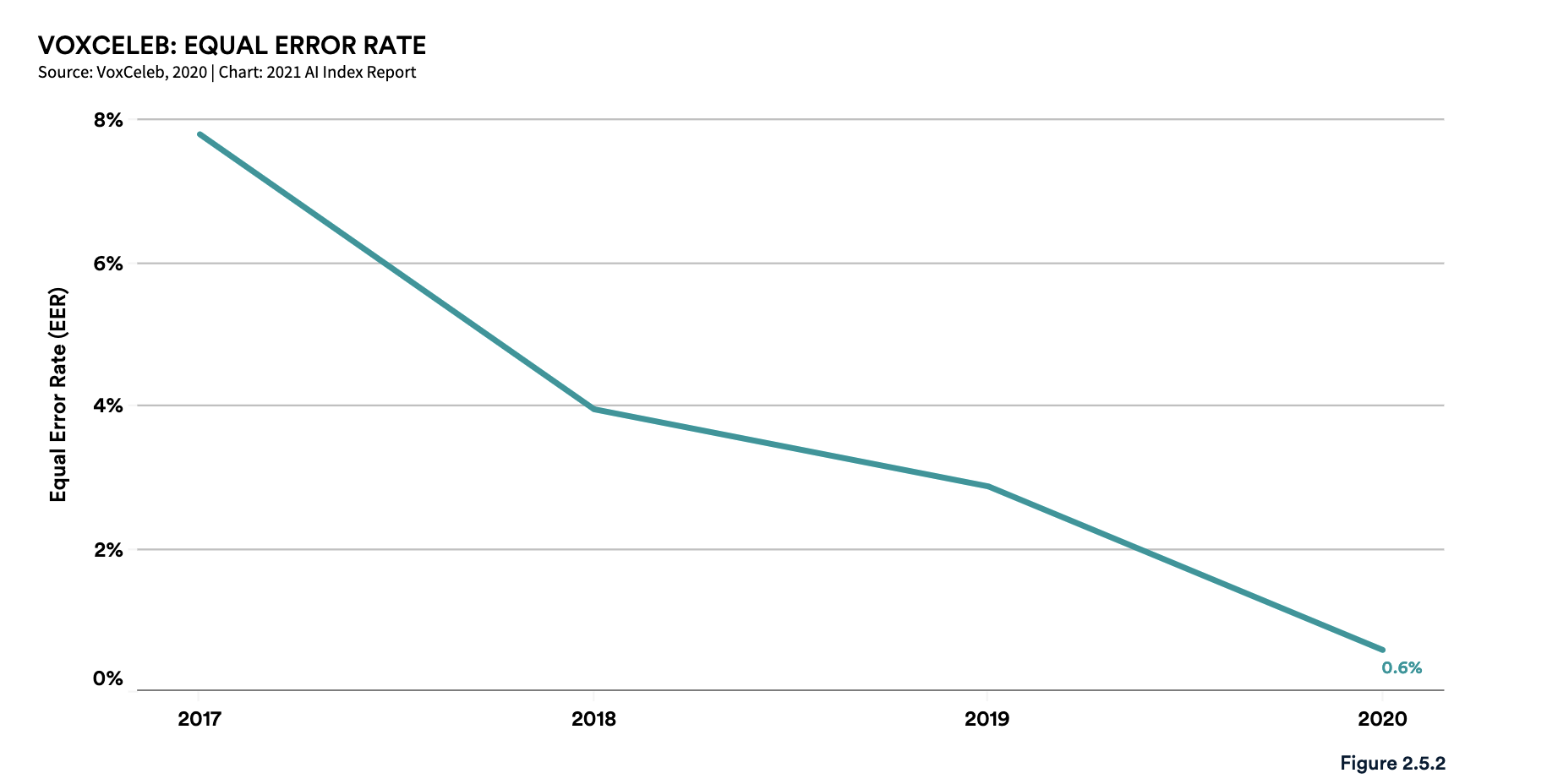 VoxCeleb Benchmark performance. Image credit: Stanford University [^6]
VoxCeleb Benchmark performance. Image credit: Stanford University [^6]
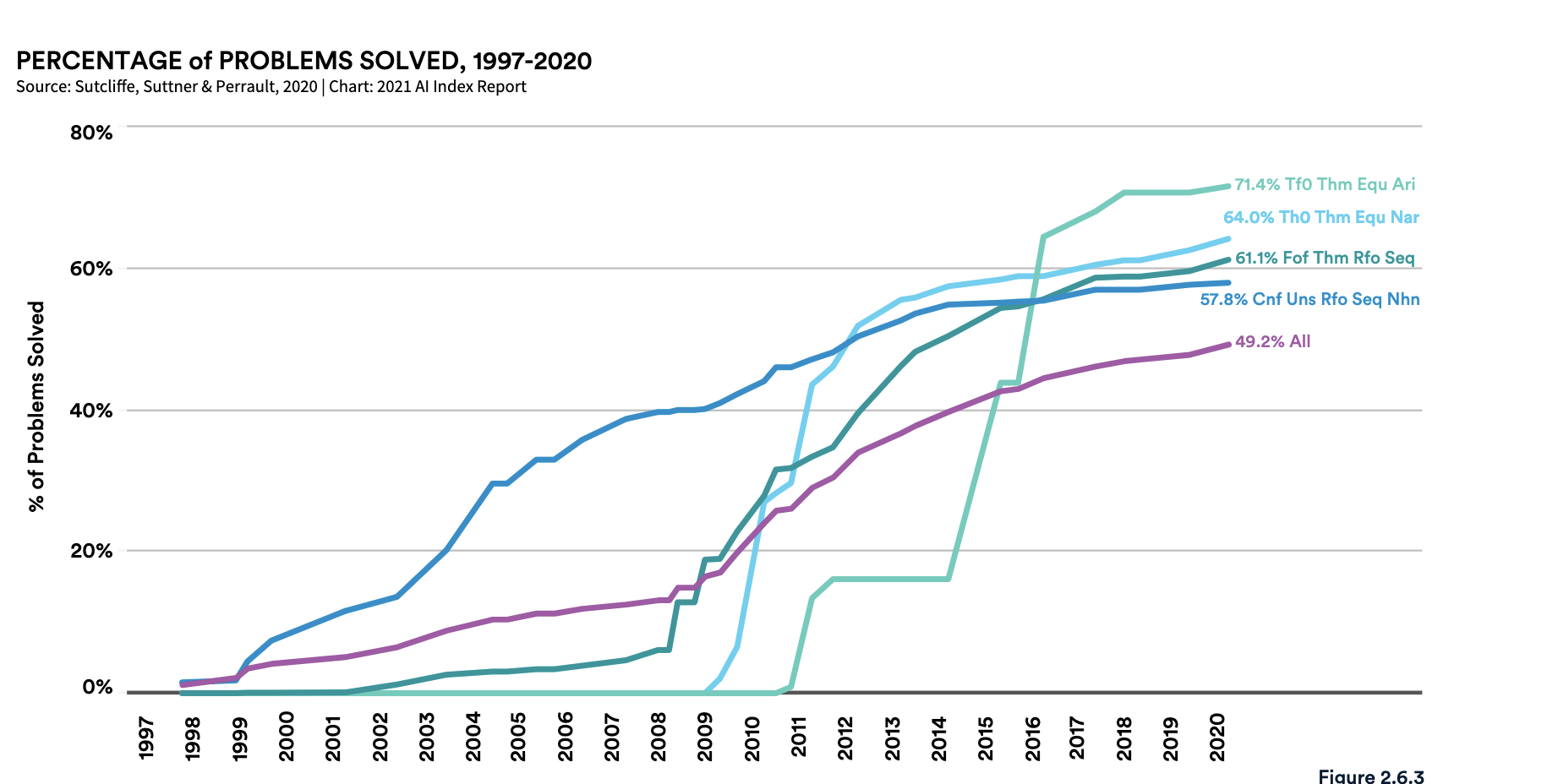 Automated Theorem Proving benchmark performance. Image credit: Stanford University [^6]
Automated Theorem Proving benchmark performance. Image credit: Stanford University [^6]
For almost anything we can benchmark, across a wide range of domains, AI systems (or Deep Learning systems, if you prefer) consistently improve until they approach human-level performance, and then in some cases they continue to get better.
Now, you might think that this is all fine, but it's foolish to extrapolate from benchmark performance to human-level intelligence. The main thing I want to stress here is: we're really bad at making predictions around when AI performance will hit a ceiling. Here are some examples of bad predictions:
- In the mid 2010s, many people expressed skepticism that computers would beat humans at Go within a decade [^7], and saw "solving Go" as the "grand challenge" of AI [^8]. In 2016, DeepMind's AlphaGo beat the top Go player 4-1 [^9].
- I couldn't find references, but I believe there was similar skepticism that AI could beat top humans at StarCraft and (way back in 1997) Chess, but of course they did.
- AI expert Gary Markus said in 2016 that Deep Learning has "no obvious way of performing logical inferences, and...integrating abstract knowledge" [^9]. As supporting evidence, he points to the fact that AI can't solve grade-school exams, and can't watch an episode of the Simpsons and answer basic questions about the content. Today, AI can do both [^10] [^11].
Of course, AI improvement will eventually level off, but there's reasons to believe it will keep going for the forseeable future.
- We don't see any slowing down, on any serious metrics. If the levelling-off is coming soon, we'd expect some aspects of performance to be already slowing down, but that's not the case
- For all sorts of tasks where people have predicted we won't solve them by just making models bigger, we've solved them by making models bigger. This suggests that we're pretty bad at figuring out what tasks are out-of-reach of such models.
- Though it's not a perfect analogy, human brains are a lot like neural networks: they're very complex but they're built out of simple components. Current-generation frontier models are still a couple of orders of magnitude less complex than brains, which suggests there is still room to grow
- Research suggests that you can get state-of-the-art results with various different neural network architectures, not just transformers (see e.g. the new RNNs, the work on ImageNet with plain MLPs, etc.). This suggests that the real insight is not the exact architecture, but the training process (which itself is very simple) and the scale (which requires a lot of complex engineering). Scaling further requires more time, money, and engineering effort, but it's fundamentally doable, and it will probably happen (just look at how much money & buzz OpenAI is getting for doing just that).
Of course, it's healthy to be skeptical of my arguments here, but my point is that you should be skeptical in both directions. No-one knows that we'll have AGI in 10 years, but no-one knows that we won't.
The case for Misaglined Goals of AGI
Firstly, why do I think that AGI will have goals? GPT-4 doesn't seem to have goals, it just has conversations.
The answer is simple: people will give it goals. Just look at AutoGPT [^12], which is exactly that.
Now, there are many academic discussions of why goal-directed agents are likely to be misaligned with human goals, and why we should expect that to end badly for us, but since I'm interested in getting the intuition across, I'm just going to list a few examples in current AI systems instead.
- Specification Gaming: often, if we give an AI system a particular goal, it will find some way to "hack" the goal without actually doing what you want it to do. DeepMind have a whole list of examples, showing that this is a harder problem than you might think [^13].
- Deception: it's possible to get all current-generation Large Language Models to say something false, and there's some evidence that they "know" what they're saying is false [^14].
- Harm from unintended behaviour: the "classic" example of this is Google Photos mis-labelling black people as gorillas, which caused serious harm, despite Google (presumably) throwing significant resources and expertise at ensuring this model was aligned with the creators' intentions [^15].
There are many more examples, and I intend to keep updating this list.
Why this could end badly for us
AI as a Powerful Weapon
If we suppose that, instead of becoming powerful agents, AIs become powerful tools, then we can still imagine a scenario where they cause significant harm to humans. Consider, for example, an AI which is capable of performing independent scientific research to answer a specific question put to it by a human. Such a capability could easily be used by bad actors to e.g. create a new biological weapon, or to exploit vulnerabilities in the global financial system.
Destabilization of Society
This one is easier, and I think clearer to see since in a way it's already happening.
If AI rapidly makes large classes of jobs obselete, then the result (at least in the short term) would be massive unemployment. One could argue that automation in the past hasn't caused unemployment to increase, but that's because (as far as I'm aware) automation generally leads to an increase in productivity and therefore economic growth, which countries can use to invest in their workforces to become more educated and to create new, higher-skilled jobs, resulting in a net benefit to everyone. The difference with AI is the speed at which these things could happen. If whole swathes of the workforce is rendered obsolete in the course of a few years or even months, that's far too fast for people to re-train or skill up.
The second major concern I have is inequality. It's plausible to me that, if frontier AI development remains prohibitively expensive and requires limited, elite talent to pull off, then the handful of organisations which are part of that frontier might gobble up the majority of the economic benefit of said AIs. This would result in massively increased inequality, potentially by orders of magnitude.
The third major concern is that specific technologies, such as text or image generation models, could rapidly erode our ability to search for the truth among mountains of AI-generated garbage. If people aren't able to even semi-reliably find truth anymore, it would call into question a foundation of many societal institutions.
Why don't we just...
Train the model to be nice?
- How do you cover the entirety of desirable & undesirable behaviour?
- Our best efforts (e.g. ChatGPT) often leave blind spots
- We might end up with a sycophant which does exactly what we ask it for, but not what we really want
Not do anything dangerous with it
Look around, people will do dangerous & dumb shit with powerful AIs if they can get their hands on them.
Bake in Asimov's 3 Laws
I could mention how Asimov's own books are about how the 3 laws are insufficient, but I can also just point out that doing this successfully would require solving a bunch of really hard problems that we're nowhere near solving (e.g. what counts as harming humans, what counts as telling the truth).
OK, so what should I, an engineer at a Fintech, do??
Apply a security mindset to AI systems. Think of the model as akin to untrusted user input.
Think critically about advocating for AI development. Bigger, better, more open models open up exciting new possibilities, but they can also be dangerous. As participants in a closely-related industry, we have a responsiblity to consider the wider societal impact of AI development. This should include, if necessary, withdrawing support (financial or otherwise) from companies we consider excessively risky or short-term. Some people would already include OpenAI among that group!
In particular, I'd ask that we don't ridicule those looking for more regulation, or to slow down AI development or adoption.
When building AI-driven systems, consider not just the current generation but the next 2 or 3 generations of model. Maybe GPT-4 is harmless when hooked up to a stock market bot, but if the code already exists it's easy to change gpt-4 to gpt-7 and suddenly our little toy moneymaker has access to serious power.
Learn more about AI Safety and AI Policy. See the next section!
What are people doing about this
Of course it's really hard to reason about machines we haven't invented yet which are smarter than us. So a lot of research is pretty foundational, just trying to figure out how we can say anything about such systems.
This research direction is generally called Agent Foundations.
There's also a lot of work going into trying to understand how neural networks work, at the mechanical level. Unlike regular interepretability or explainability work in Machine Learning, this is about fully understanding the way that a model arrived at a conclusion. The test for fully understanding is being able to reconstruct the neural network from scratch.
Though it's ambitious, several research directions constitute full plans for building AIs which are aligned with human interests, or adjusting existing AIs so that they are aligned. Some things to google for are:
- Iterative Distillation & Amplification
- Microscope AI
- Open Agency Architecture
- Scalable Alignment via Human Feedback
For more on this, check out the AI Safety Landscape article (insert link here).
Further Reading
Nothing I've written here is remotely original.
For an alternative introduction to the problem of AI Alignment, I can recommend these blog posts [^16] [^17] (this one is from Yoshua Bengio, one of the founders of deep learning). I can also recommend Robert Miles's Youtube channel [^18].
If you'd like to read more, two accessible and excellent books are Brian Christian's "The Alignment Problem" and Stuart Russell's "Human Compatible" (Stuart Russell is co-author of the most popular AI textbook in the world).
If you're looking for something more rigorous, these reports [^19] [^20] cover the arguments with as much academic rigor as you might like.
Finally, if you'd like more details on the technical research, I can recommend "Concrete Problems in AI Safety" [^21] or the GPT-4 System Card [^22].
References
1: "2022 Expert Survey on Progress in AI", 2022, AI Impacts
3: "Will there be Human-machine intelligence parity before 2040?", Metaculus
4: "Forecasting AI with Bio Anchors", 2020, Ajeya Cotra / Open Philanthropy
5: "What a compute-centric framework says about takeoff speeds", 2023, Tom Davidson / Open Philanthropy
6: "AI Index Report", 2021, Stanford University
7: "The Mystery of Go, the Ancient Game Computers Can't Win", 2014, Wired
8: "Computer go: a grand challenge for AI", 2007
9: "Why Toddlers are smarter than computers", 2007, Gary Markus (video)
10: "GPT-4 Technical Report", 2022, OpenAI
12: AutoGPT github
13: "Specification Gaming: the flip side to AI Ingenuity", 2020, Victoria Krakovna / Deepmind
14: "The Internal State of an LLM Knows When It's Lying", 2023, A. Azaria & T. Mitchell
16: "Why AI alignment could be hard with modern deep learning", 2021, Ajeya Cotra
17: "How Rogue AIs might arise", 2023, Yoshua Bengio
18: Robert Miles's Youtube Channel
19: "Is Power-seeking AI an Existential Risk?", 2022, Joseph Carlsmith
20: "The Alignment Problem from a Deep Learning Perspective", 2023, R. Ngo, S. Minderman, L. Chan